
Despite the rapid growth of AI research in healthcare, its real-world adoption lags significantly behind other industries. To close this gap, a group of researchers from the University of Applied Sciences and Arts Northwestern Switzerland, ETH Zurich, and the University of Bern proposed 'AI for IMPACTS' – a framework designed to assess AI’s translational readiness in real-world healthcare settings.
Numerous challenges continue to hinder integration, including trust issues, concerns over accuracy and reliability, difficulties in reproducing results, and a complex web of ethical, legal, and societal implications. Additionally, while various frameworks have emerged to evaluate AI in healthcare, there remains a critical gap: a comprehensive, systematic approach that not only assesses real-world impact but also provides clear guidance on clinical implementation, monitoring, procurement, and evaluation.
To bridge this critical gap, the "AI for IMPACTS Framework for Evaluating the Long-Term Real-World Impacts of AI-Powered Clinician Tools," published in JMIR, introduces a comprehensive approach that extends beyond traditional clinical studies. This framework responds to the urgent need for a robust, systematic tool to assess AI’s translational readiness in real-world healthcare settings, offering a structured pathway for implementation, integration, and monitoring.
Rethinking AI evaluation for real-world healthcare impact
Despite the rapid advancement of AI in healthcare, existing evaluation approaches fall short in several critical areas, hindering meaningful integration into clinical practice. Key challenges include:
Outdated Assessment Frameworks: Traditional technology evaluations often fail to address the dynamic and evolving nature of AI in healthcare. Traditional HTA frameworks lack the adaptability required to assess AI’s unique challenges, real-world complexities, and long-term impact.
Lack of Standardized Evaluation Beyond Clinical Trials: While several reporting frameworks exist for clinical trials, there is no globally accepted standard for assessing AI tools beyond controlled research settings. Without a unified, comprehensive framework, AI adoption remains fragmented, with no clear path from development to practical implementation.
Regulatory Blind Spots: Regulatory approvals, such as FDA clearances and emerging laws like the EU AI Act, aim to ensure the safety and reliability of AI-driven healthcare tools. However, significant gaps remain; a recent study showed that nearly half of FDA-approved AI devices lack clinical validation data, raising concerns about their real-world effectiveness and potential risks to patient care.
Implementation Challenges: Existing guidelines largely overlook the complex, multi-phase process required to seamlessly integrate AI into clinical workflows. This results in limited guidance on how to scale, sustain, and monitor AI tools once deployed.
Over-Reliance on Technical Metrics: AI evaluation in healthcare continues to be dominated by traditional performance indicators such as sensitivity and specificity. While these are important, they fail to capture broader clinical outcomes, usability, and long-term impact on patient care.
To truly harness AI’s potential in healthcare, we must move beyond fragmented, trial-focused evaluations and establish a comprehensive framework that not only measures AI’s performance in controlled environments but also assesses its real-world adoption, clinical impact, and long-term sustainability. The next step is clear: rethinking how we evaluate AI to ensure it delivers tangible, lasting benefits for both healthcare providers and patients.
An instrument to assess AI’s translational readiness in healthcare
By systematically reviewing existing assessment frameworks and synthesizing key findings, the authors of this study developed a comprehensive framework that moves beyond traditional evaluation approaches, which often focus narrowly on technical metrics or study-level methodologies. Instead, it incorporates critical real-world implementation factors and clinical context, offering a more holistic and practical approach to assessing AI tools in healthcare.
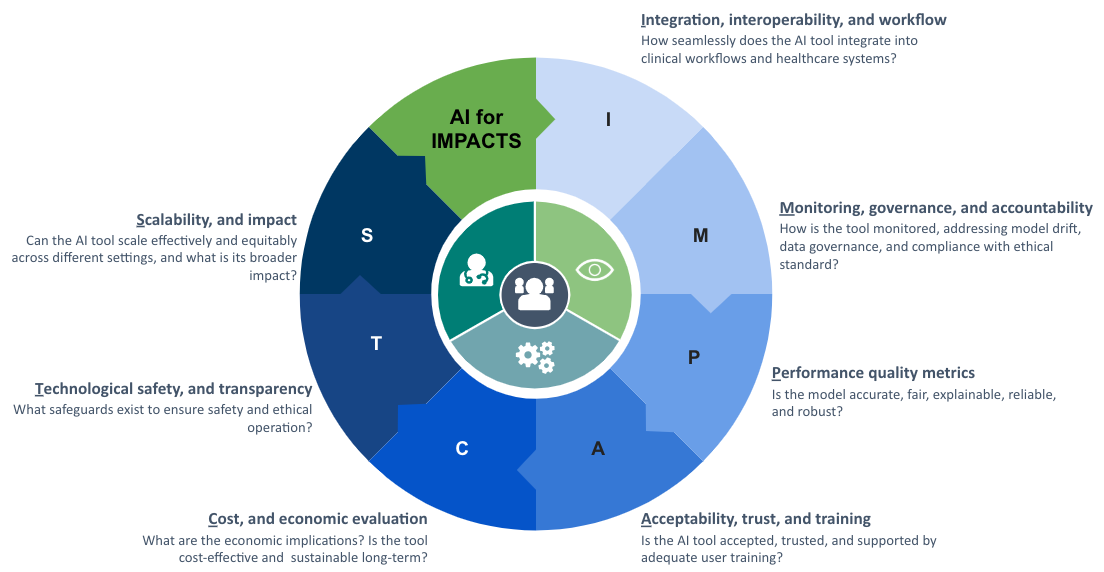
With a strong emphasis on measuring the long-term, real-world impact of AI technologies, the authors introduced the AI for IMPACTS framework. The evaluation criteria are structured into seven key domains, each representing a crucial aspect of AI adoption in healthcare:
I – Integration, Interoperability, and Workflow
M – Monitoring, Governance, and Accountability
P – Performance and Quality Metrics
A – Acceptability, Trust, and Training
C – Cost and Economic Evaluation
T – Technological Safety and Transparency
S – Scalability and Impact
These seven dimensions are further broken down into 28 specific subcriteria, creating a structured yet adaptable tool for evaluating AI in the complex healthcare landscape. However, a critical challenge in AI evaluation is the lack of multidisciplinary expertise among assessors. Many stakeholders involved in AI assessment lack the necessary training, while traditional evaluation methods struggle to keep pace with AI’s rapid advancements. To ensure responsible and effective AI integration into healthcare, assessment processes must become more dynamic, flexible, and responsive, balancing rigorous evaluation standards with the agility required to adapt to AI’s evolving landscape.
The urgent need for a more comprehensive, stakeholder-driven approach
"Our in-depth review of AI assessment studies uncovered significant methodological gaps, including missing or insufficiently detailed methods sections, lack of analytical rigor, and minimal real-world validation involving key stakeholders," explains Christine Jacob, project lead and first author of the study. "These deficiencies may weaken the credibility and relevance of existing evaluation frameworks and reinforce the urgent need for a more comprehensive, stakeholder-driven approach."
To address this, the research team is actively seeking partners and funding to support the validation of the AI for IMPACTS framework. The goal is to establish stakeholder consensus on a robust AI assessment instrument, one that balances the diverse and sometimes conflicting priorities of key players across the healthcare ecosystem.






